👋 Salut la Team IA !
Voici le sommaire de la semaine :
📹️ Ma Semaine en Direct → Retour YouTube + un petit cadeau musical (2 min)
🤖 Tip IA du Jour → Comment j’ai construit ma machine à générer du contenu IA (8 min)
📺 Le Replay de la semaine → Pas de vidéo, mais un Live à 18h30 (1 min)
📰 L’actu IA
⏱️ Temps de lecture total estimé : 11 minutes
👉 Développez vos solutions IA dès maintenant : Azuro AI
👉 Rejoignez mon Skool : Le Club IA
📹️ Ma Semaine en Direct
J’espère que vous avez kiffé l’été 🌞
De mon côté, gros reset : nouvel appart, nouveau matos, nouveau décor → le retour YouTube va être 🔥

nouveau décor !
Septembre s’annonce chargé !
🎁 Petit cadeau : si vous aimez bosser avec de la musique focus → Flowtunes → 100% gratuit, zéro pub, une vraie pépite découverte hier 🎧
🤖 Tip IA du Jour
Imagine…

Un matin en novembre.. Il fait froid dehors.
Tu te lèves doucement, tu fais chauffer ton café.
Tu poses tes mains autour de la tasse encore fumante, tu ouvres ton téléphone.
Une vidéo sur Instagram : Une femme sourit, son discours est fluide, son regard accroche l’écran.
Et puis… un détail.
L’œil cligne, mais pas de façon tout à fait naturelle.
Une micro-déviation, presque imperceptible, mais qui suffit à te troubler.
Et là, tu réalises.

Ce n’est peut-être pas une actrice.
Ce n’est peut-être même pas une personne.
Tu viens de voir le dernier défaut d’un contenu généré par l’IA.
Bientôt, il n’y en aura plus.
L’état des lieux
Aujourd’hui,
Tous les composants de la machine parfaite pour créer du contenu avec l’IA sont déjà là.

fal.ai
Les briques existent. Les modèles sont puissants.
Avec les bons outils et les bonnes méthodes,
On peut déjà les assembler pour construire une véritable machine à générer du contenu.
Et c’est précisément ce que j’ai fait ces 4 à 5 derniers mois en me plongeant à fond dans ce domaine pour plusieurs clients chez Azuro AI.
+300 nœuds, +50 workflows, 5 Versions
J’ai passé des semaines à aligner les outils, tester les workflows, regarder ce qu’il se fait déjà et le constat est sans appel :
Le contenu 100% IA est déjà à la hauteur..
Des personnages virtuels qui n’existent pas, mais qui témoignent comme s’ils avaient utilisé un produit.
Ces pubs tournent sur YouTube, Instagram, TikTok, Google… et elles performent déjà mieu que des vraies.
Le contenu social, lui, est plus exigeant.
La pub, tu la pousses avec un budget.
Mais un post organique doit convaincre l’algorithme.
Ce qui veut dire : une qualité irréprochable.
Aujourd’hui, on est déjà à 70–80 % de la qualité nécessaire. (mon estimation)
Ce qui fait la différence, ce n’est pas d’utiliser les outils isolément, mais de savoir les orchestrer en workflows cohérents et puissants.
pas le vrai workflow..
Et demain ?
La qualité ne fera qu’augmenter.
Les prix ne feront que baisser.
Ceux qui auront déjà monté leur “machine” seront en première ligne.
C’est comme savoir assembler une voiture.
Tu as déjà toutes les pièces en main : le châssis, les roues, la carrosserie.
Quand les nouveaux moteurs et les nouvelles pièces sortiront..
Tu sauras monter une Lamborghini.

vroum vroum..
⚠️ Ma boîte à outils et mon process dévoilé
Une énorme partie de ce système SMM repose sur quelque chose qu’on néglige souvent :
la préparation des données.
Avant même de parler d’images, de voix ou de vidéos, il faut savoir traiter la matière brute.
Et là, c’est un vrai travail d’architecte.
il est drôle ce gif non ?
Mon process commence par combiner plusieurs briques :
des outils de scrapping,
des techniques de code,
de l’assainissement et du formatage de données,
et bien sûr, du prompting intelligent.
Pourquoi ?
Pour pouvoir traiter absolument n’importe quel type de contenu :
vidéos (youtube/insta/tiktok),
audio (podcast, notes vocales),
pages web (articles, sites complets),
documents PDF, Excel,
et avec des outils comme Apify, on va encore plus loin :
profils entiers de réseaux sociaux (contenus, commentaires, likes, tout).

les sub workflows qui traitent le contenu
Tout ce matériau est ensuite analysé et évalué avec un score de viralité basé sur différents signaux :
nombre de vues, de likes, de partages, mais aussi l’analyse des commentaires.
Étape 1 : uniformiser
Transformer toutes ces sources disparates en un fichier texte uniformisé, parfaitement structuré et prêt pour les étapes suivantes de génération avec l’IA.
Étape 2 : résumer et structurer
Exemple avec une vidéo :
Je la résume en chapitres clairs.
Chaque chapitre devient une idée de contenu.
À partir de ces idées, je génère un script global.
Étape 3 : découper en séquences
Ce script est découpé en parties de 5 à 10 secondes.
Pourquoi ?
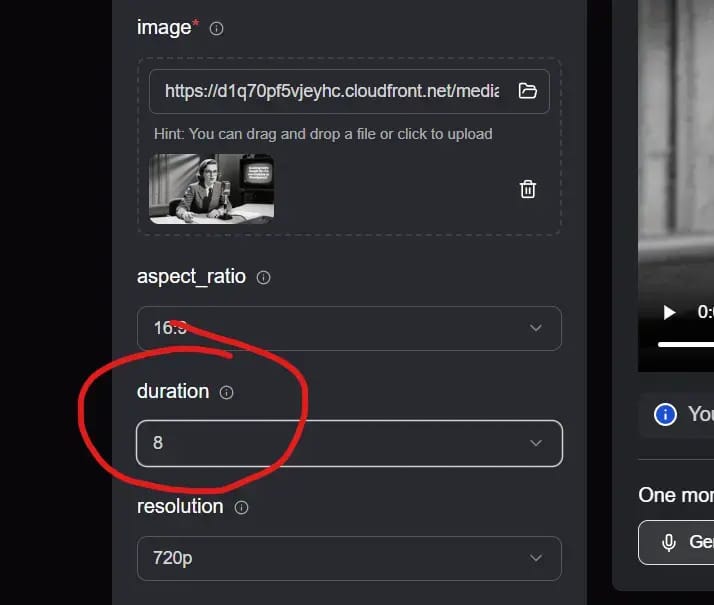
veo3 = 8 sec max
Parce que c’est la limite des générateurs vidéo actuels :
Veo3 = max 8 secondes
Kling AI = max 10 secondes
Étape 4 : créer les images
Pour chaque séquence :
ReCraft si je veux une vraie constance visuelle,
Flux si je veux la meilleure qualité d’image,
gpt-image-1 si vous êtes fanboy d’OpenAI.

Spoiler : je suis 100% FLUX
Étape 5 : générer la voix
Une fois le script en main :
Je passe par ElevenLabs,
je choisis la voix, la langue, et je peux même cloner la mienne.
Étape 6 : donner vie aux images
Ensuite, j’anime ces images avec Kling 2.1 en mode image-to-video.

kling ai
Petit bonus : avec Lips Sync, je peux synchroniser les lèvres d’un avatar avec la voix générée.
Étape 7 : enrichir l’expérience
Toujours via ElevenLabs, j’ajoute au besoin des bruitages réalistes :
une cuisine → bruits de vaisselle,
une rue → ambiance urbaine, etc.
Étape 8 : assembler et magnifier
Enfin, je passe tout sur Creatomate :
assemblage complet,
transitions,
effets,
musique,
sous-titres auto-générés.
creatomate.com
Et c’est là que la créativité prend le relais. Les possibilités sont infinies.
Bref..
🎁 Vous voulez récupérer directement mes workflows n8n ?

Trois sont déjà disponibles dans mon Skool, juste ici : 👉 Accéder aux workflows n8n
Où tout ça nous mène ?
Soyons clairs :
On arrive à une époque où il sera..
im-po-ssible de distinguer une vidéo IA d’une vidéo réelle.
Pas en 2050.
Pas dans 20 ans.
Dans quelques années à peine (ou mois ?)
La vraie question, ce n’est pas si ça va arriver.
C’est : qui sera prêt ?
Pourquoi je vous en parle aujourd’hui
Je vous parle de ça aujourd’hui parce que je veux vraiment que vous ouvriez les yeux sur ce qui est déjà faisable dès maintenant.
Et surtout que vous soyez acteurs de cette révolution, pas simples spectateurs.
Tous les outils sont là.
Les modèles sont déjà hyper puissants.
Et demain, ceux qui sauront orchestrer ces outils deviendront les pionniers.
La question est simple :
Est-ce que tu en feras partie ?
Un espace où je partage mes workflows, mes tests, mes méthodes.
En le rejoignant, vous pourrez récupérer tous mes workflows complets pour la génération de contenu avec l’IA.
Et ce n’est que le début :
Je prépare une série entière sur Skool, avec des tutoriels précis pour apprendre à générer du contenu.
Et très bientôt, Skool Premium ouvrira ses portes : une formation A à Z pour créer les mêmes contenus que nous produisons chez Azuro AI.
Des contenus que nos clients paient déjà… plusieurs milliers d’euros.
📺 Le Replay de la semaine
Pas de vidéo cette semaine non plus.
On fait une petite pause en août pour revenir à 200% dès la semaine prochaine !
Mais… gros live ce soir à 18h30 🎥
Rejoignez-nous ici → Live Skool
Posez vos questions en direct et venez parler IA 👊
📰 L’actu IA
🖌️ Qwen Image Edit (Alibaba) – le Photoshop open-source qui défie Adobe
Le 19 août 2025, Alibaba a sorti une bombe : un modèle d’édition d’images de 20 milliards de paramètres, open-source (Apache 2.0), gratuit et accessible à tous.
👉 Points clés :
Double architecture (édition sémantique pour transformations globales + édition d’apparence pour modifications locales).
Spécialiste du text editing bilingue (anglais/chinois) sans casser la typographie.
Compatible avec toutes les résolutions de 512×512 à 4096×4096.
Fonctionne dès 4 Go de VRAM (8 Go recommandé).
Déjà intégré à Replicate et ComfyUI.
Où le tester ?
🍌 “Nano Banana” (Google) – le modèle mystère enfin révélé
Apparu anonymement sur LM Arena mi-août, ce modèle a buzzé avant que Google annonce officiellement son Gemini 2.5 Flash Image le 26 août.
👉 Pourquoi c’est énorme ?
Cohérence parfaite des personnages d’une image à l’autre.
Édition multi-tours fluide, sans perte de qualité.
Une vitesse inédite : 1–2 secondes par génération (vs 10–15 pour les concurrents).
Intégration native avec la base de connaissances Gemini → édition contextuelle intelligente.
Déjà #1 sur LM Arena.
Où l’utiliser ?
🎥 Higsfield AI – la vidéo dirigée par… un dessin
La startup de SF Higsfield AI (ex-leader IA chez Snapchat à la tête) a lancé en août 2025 son outil Draw-to-Video.
Ici, pas de prompt.
👉 Tu places directement un produit ou un objet dans une scène, tu gribouilles quelques annotations visuelles, et l’IA génère la vidéo cinématique correspondante.
Caractéristiques marquantes :
Placement produit direct + changement de tenues par simple ajout visuel.
+50 mouvements de caméras pros intégrés (dolly, bullet time, crash zoom…).
Vidéos de 10 secondes max (record actuel) + upscale 4K via Topaz Labs.
Création d’avatars depuis selfie.
Optimisation native TikTok, Insta, YouTube.
Tarifs : Gratuit avec watermark → Creator à 249$/mois pour 6000 crédits.
🎮 Runway Game Worlds – du texte au jeu interactif
Le 21 août, Runway a dévoilé Game Worlds Beta : une plateforme qui transforme un simple prompt en jeu interactif narratif.
👉 Deux modes disponibles :
Chat Mode → aventure textuelle classique.
Comic Mode → version illustrée avec images générées.
Exemples déjà jouables :
The Last Score (jeu de braquage),
Athena Springs (mystère angoissant),
The Gallic Storm (narratif historique).
Caractéristiques techniques :
Génération narrative temps réel.
Images dynamiques au fil de l’histoire.
Mémoire persistante des personnages.
Sauvegarde/reprise des parties.
👉 C’est encore limité (pas de vidéo, pas d’app mobile).
Mais Runway promet déjà des jeux vidéo générés d’ici fin 2025.
🎶 ElevenLabs Video-to-Music – la bande son générée automatiquement
Déjà leader sur la voix IA, ElevenLabs passe à la musique vidéo.
Leur outil analyse automatiquement scènes, couleurs, ambiance, rythme → et génère une bande sonore parfaitement adaptée.
👉 Caractéristiques pros :
Audio 44.1kHz stéréo, 4 min max.
Tous genres et moods possibles.
Sortie MP3 jusqu’à 192 kbps.
Synchronisation parfaite visuel/audio.
Moteur dispo dans ElevenLabs Studio + API en préparation.
En août, ils ont signé des deals avec Merlin Network et Kobalt Music Group → certaines tracks incluent même des styles inspirés d’artistes comme Adele, Nirvana, Beck.
C’est tout pour cette semaine !
On se retrouve bientôt, continuez d'avancer !
Thomas 🦾
